USMA1Q — Méthodes Numériques¶
Séance 9 — Intégration numérique II : méthodes de Monte Carlo¶
Conservatoire National des Arts et Métiers
25 Mars 2026
nicholas-anton.collins-craft@enpc.fr
Un lien vers Google Colab qui peut faire tourner le notebook qui contient les exercices se trouve ici :
https://colab.research.google.com/github/nickcollins-craft/USMA1Q-Methodes-Numeriques/blob/main/
Plan du cours¶
| Jour | Sujet |
|---|---|
| 03 mars | Fondamentaux de la programmation en Python |
| 04 mars (matin) | Fonctions, listes approfondies, fichiers et graphiques |
| 04 mars (après-midi) | Calcul numérique avec NumPy |
| 11 mars (matin) | Tableaux en mémoire, matrices & précision numérique |
| 11 mars (après-midi) | Résolution des systèmes linéaires |
| 18 mars (matin) | Interpolation & recherche des racines |
| 18 mars (après-midi) | Systèmes d'équations non linéaires |
| 25 mars (matin) | Intégration numérique I |
| 25 mars (après-midi) | Intégration numérique II (Monte Carlo) |
| 02 avril | Équations différentielles |
| 08 avril | Examen |
Plan de la séance (indicatif)¶
| Horaire | Sujet |
|---|---|
| 0:00 – 1:05 | Fondamentaux de l'intégration Monte Carlo |
| 1:05 – 1:50 | Intégration Monte Carlo en plusieurs dimensions |
| 1:50 – 2:00 | ☕ Pause |
| 2:00 – 2:40 | Réduction de variance & échantillonnage pondéré |
| 2:40 – 3:40 | Mini-projet noté : analyse d'un alliage à mémoire de forme |
| 3:40 – 3:45 | Récapitulatif |
0. Motivation¶
Nous avons vu des méthodes déterministes d'intégration :
Newton–Cotes : trapèzes, Simpson
- Pour données discrètes ou grilles régulières
- Erreur $\mathcal{O}(h^2)$ et $\mathcal{O}(h^4)$
Quadrature de Gauss–Legendre
- Choix optimal des nœuds et poids
- $N$ points : intègre exactement les polynômes de degré $\leq 2N-1$
scipy.integrate.quad(): quadrature adaptative automatique
Problème en haute dimension : si on a $d$ dimensions et $N$ points par axe, on a besoin de $N^d$ évaluations !
Exemple : $d=10$, $N=100$ → $100^{10} = 10^{20}$ évaluations — impossible !
1 · Intégration Monte Carlo : idée de base¶
Idée : estimer une intégrale par échantillonnage aléatoire, pas par une grille régulière.
Considérons l'intégrale 1D :
$$I = \int_a^b f(x)\,\mathrm{d}x$$
On peut la réécrire comme :
$$I = (b - a) \times \frac{1}{b-a}\int_a^b f(x)\,\mathrm{d}x = (b - a) \times \langle f \rangle$$
où $\langle f \rangle$ est la valeur moyenne de $f(x)$ sur $[a,b]$.
Estimateur Monte Carlo¶
Tirons $N$ points $x_1, x_2, \ldots, x_N$ uniformément dans $[a,b]$ :
$$\hat{I}_N = (b - a) \times \frac{1}{N}\sum_{i=1}^N f(x_i)$$
Par la loi des grands nombres : $\hat{I}_N \to I$ quand $N \to \infty$
Erreur estimée (théorème central limite) :
$$\text{erreur standard} = (b - a) \times \frac{\sigma_f}{\sqrt{N}}$$
où $\sigma_f = \sqrt{\langle f^2 \rangle - \langle f \rangle^2}$ est l'écart-type empirique de $f$ sur les $N$ échantillons.
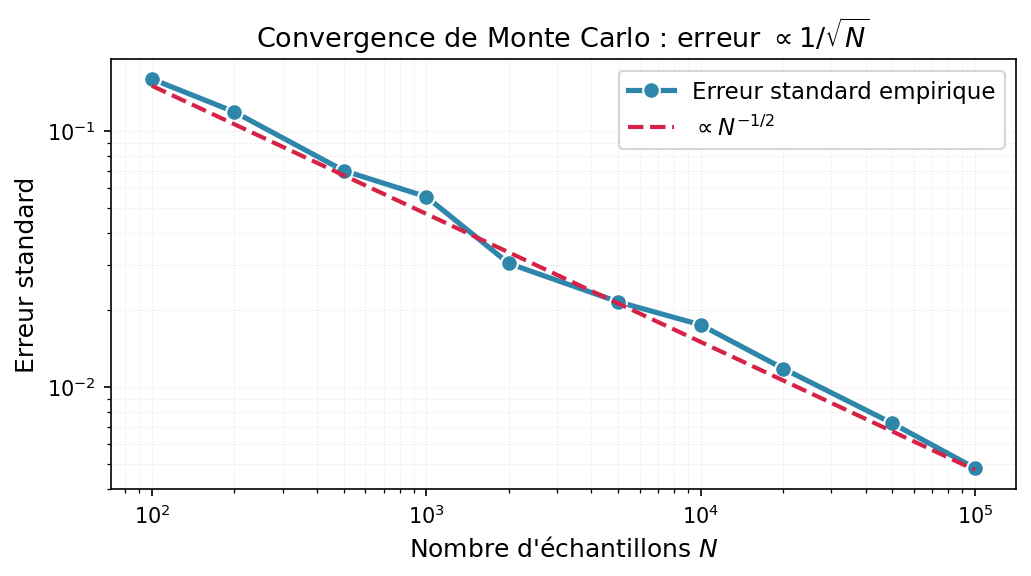
Propriété clé : convergence en $1/\sqrt{N}$¶
$$\text{erreur} \propto \frac{1}{\sqrt{N}}$$
- Pour réduire l'erreur d'un facteur 10, il faut 100 fois plus d'échantillons
- Pour avoir un chiffre significatif de plus, il faut multiplier par 100 le nombre d'échantillons
⚠️ Comparaison : Simpson converge en $\mathcal{O}(N^{-4})$ en 1D, beaucoup plus rapide !
Mais en dimension $d$, Simpson nécessite $N^d$ évaluations, alors que Monte Carlo ne dépend pas de $d$ !
Règle pratique : utiliser Monte Carlo quand :
- La dimension $d \geq 4$ ou 5
- La région d'intégration est complexe ou irrégulière et donc difficile à exprimer analytiquement
- Peu de précision est nécessaire (quelques chiffres significatifs)
Exemple 1 : intégrer $f(x) = 4/(1+x^2)$ sur $[0,1]$¶
Valeur exacte : $\int_0^1 \frac{4}{1+x^2}\,\mathrm{d}x = 4\arctan(1) = \pi$
Nous allons estimer $\pi$ par Monte Carlo !
import numpy as np
import matplotlib.pyplot as plt
# Créer un générateur de nombres aléatoires moderne
rng = np.random.default_rng(seed=42) # seed=42 pour reproductibilité
def monte_carlo_1d(f, a, b, N, rng):
"""Intégration Monte Carlo 1D simple."""
# Tirer N points uniformément dans [a, b]
x = rng.uniform(a, b, N)
# Évaluer f sur ces points
fx = f(x)
# Estimateur de l'intégrale
I_hat = (b - a) * np.mean(fx)
# Erreur standard
sigma = np.std(fx, ddof=1) # ddof=1 pour correction de Bessel (on prends un échantillon de la population)
err = (b - a) * sigma / np.sqrt(N)
return I_hat, err
# Fonction à intégrer
def f(x):
return 4.0 / (1.0 + x**2)
# Estimer π
N = 100000
I_hat, err = monte_carlo_1d(f, 0, 1, N, rng)
print("Estimation Monte Carlo avec N =", N, ":")
print("I_hat = ", round(I_hat, 6))
print("erreur standard = ", round(err, 6))
print("valeur exacte (π) = ", round(np.pi, 6))
print("erreur réelle = ", round(abs(I_hat - np.pi), 6))
Estimation Monte Carlo avec N = 100000 : I_hat = 3.140141 erreur standard = 0.002032 valeur exacte (π) = 3.141593 erreur réelle = 0.001452
Vérification empirique : convergence en $1/\sqrt{N}$¶
Répétons l'estimation pour différentes valeurs de $N$ et observons la décroissance de l'erreur.
# Pour chaque N, répéter 50 fois et enregistrer l'erreur
N_vals = [100, 1000, 10000, 100000]
n_repeat = 50
for N in N_vals:
errors = []
for _ in range(n_repeat):
I_hat, _ = monte_carlo_1d(f, 0, 1, N, rng)
errors.append(abs(I_hat - np.pi))
mean_error = np.mean(errors)
std_error = np.std(errors, ddof=1)
print("N = ", str(N).ljust(6), " | erreur moyenne = ",
str(round(mean_error, 6)).ljust(6), " | std(erreur) = ", str(round(std_error, 6)).ljust(6))
N = 100 | erreur moyenne = 0.045044 | std(erreur) = 0.035195 N = 1000 | erreur moyenne = 0.014333 | std(erreur) = 0.010746 N = 10000 | erreur moyenne = 0.005305 | std(erreur) = 0.003722 N = 100000 | erreur moyenne = 0.001629 | std(erreur) = 0.001178
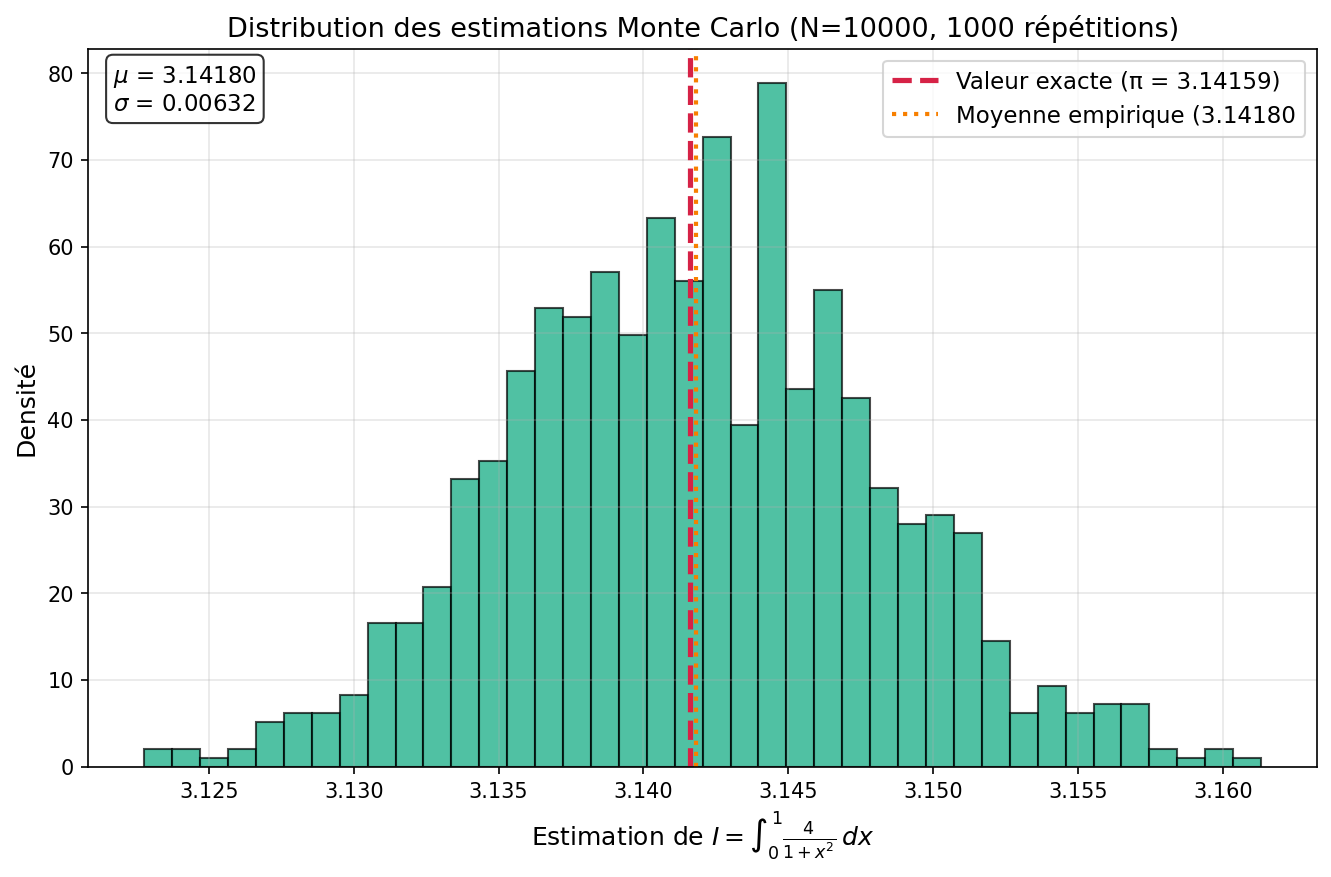
Distribution des estimations¶
Le théorème central limite prédit que les estimations $\hat{I}_N$ suivent une distribution normale autour de la vraie valeur.
# Répéter 1000 fois avec N = 10000
N = 10000
n_repeat = 1000
estimates = []
for _ in range(n_repeat):
I_hat, _ = monte_carlo_1d(f, 0, 1, N, rng)
estimates.append(I_hat)
estimates = np.array(estimates)
print("Moyenne des estimations :", round(np.mean(estimates), 6))
print("Écart-type des estimations :", round(np.std(estimates, ddof=1), 6))
print("Valeur exacte (π) :", round(np.pi, 6))
Moyenne des estimations : 3.141559 Écart-type des estimations : 0.006388 Valeur exacte (π) : 3.141593
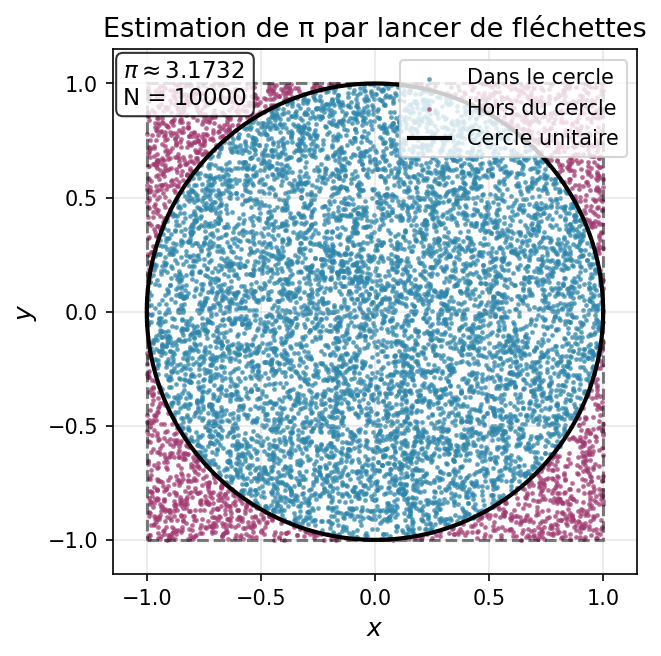
Exemple célèbre : estimer π en lançant des fléchettes 🎯¶
Considérons un carré de côté 2 centré à l'origine, et un cercle de rayon 1 inscrit dedans.
- Aire du carré : $A_{\text{carré}} = 4$
- Aire du cercle : $A_{\text{cercle}} = \pi$
Rapport des aires : $\frac{A_{\text{cercle}}}{A_{\text{carré}}} = \frac{\pi}{4}$
Méthode :
- Lancer $N$ points aléatoires $(x, y)$ uniformément dans le carré $[-1,1] \times [-1,1]$
- Compter combien sont dans le cercle : $x^2 + y^2 \leq 1$
- Estimer : $\pi \approx 4 \times \frac{\text{nb. dans cercle}}{N}$

# Estimer π par « dartboard method »
N = 100000
rng = np.random.default_rng(seed=123)
# Tirer N points dans le carré [-1, 1] × [-1, 1]
x = rng.uniform(-1, 1, N)
y = rng.uniform(-1, 1, N)
# Tester si chaque point est dans le cercle
inside = (x**2 + y**2) <= 1.0
# Estimer π
pi_estimate = 4.0 * np.sum(inside) / N
print("Estimation de π avec N = :", N)
print("Estimation de π :", round(pi_estimate, 6))
print("Valeur exacte de π :", round(np.pi, 6))
print("Erreur :", round(abs(pi_estimate - np.pi), 6))
Estimation de π avec N = : 100000 Estimation de π : 3.14308 Valeur exacte de π : 3.141593 Erreur : 0.001487
À vous de faire les exercices 1.1 — 1.4 !¶
2 · Intégration Monte Carlo en plusieurs dimensions¶
La vraie force de Monte Carlo apparaît en haute dimension.
Pour une intégrale sur un hyperrectangle en $d$ dimensions :
$$I = \int_{a_1}^{b_1}\cdots\int_{a_d}^{b_d} f(\mathbf{x})\,\mathrm{d}\mathbf{x}$$
L'estimateur Monte Carlo est :
$$\hat{I}_N = V \times \frac{1}{N}\sum_{i=1}^N f(\mathbf{x}_i)$$
où $V = \prod_{j=1}^d (b_j - a_j)$ est le volume de l'hyperrectangle, et chaque $\mathbf{x}_i$ est tiré uniformément.
Convergence : encore $\mathcal{O}(1/\sqrt{N})$, indépendamment de $d$ !
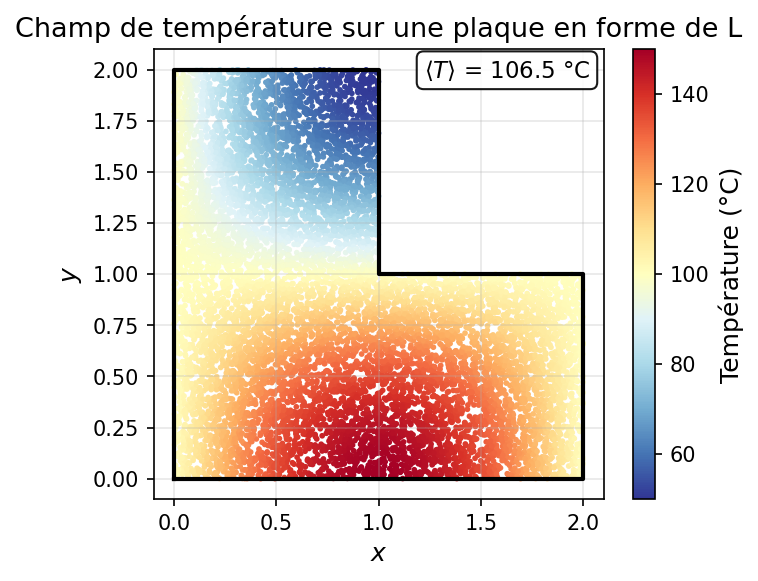
Exemple 2D : champ de température sur une plaque en forme de L¶
Soit une plaque en forme de L (région non rectangulaire), avec un champ de température :
$$T(x,y) = 100 + 50\sin\left(\frac{\pi x}{2}\right) \cos\left(\frac{\pi y}{2}\right)$$
On veut calculer la température moyenne sur la plaque.
Stratégie Monte Carlo :
- Tirer des points $(x,y)$ uniformément dans un rectangle englobant
- Rejeter ceux qui sont hors de la région en L
- Calculer la moyenne de $T(x,y)$ sur les points retenus
# Région en forme de L : union de deux rectangles
# Rectangle 1 : [0, 2] × [0, 1]
# Rectangle 2 : [0, 1] × [1, 2]
def inside_L_shape(x, y):
"""Renvoie True si (x, y) est dans la région en L."""
rect1 = (0 <= x) & (x <= 2) & (0 <= y) & (y <= 1)
rect2 = (0 <= x) & (x <= 1) & (1 < y) & (y <= 2)
return rect1 | rect2
def temperature(x, y):
"""Champ de température T(x, y)."""
return 100 + 50 * np.sin(np.pi * x / 2) * np.cos(np.pi * y / 2)
# Rectangle englobant : [0, 2] × [0, 2]
rng = np.random.default_rng(seed=456)
N = 500000
x = rng.uniform(0, 2, N)
y = rng.uniform(0, 2, N)
# Filtrer les points dans la région L
mask = inside_L_shape(x, y)
x_inside = x[mask]
y_inside = y[mask]
# Calculer la température moyenne
T_vals = temperature(x_inside, y_inside)
T_mean = np.mean(T_vals)
# Aire de la région L
A_L = 2*1 + 1*1 # Rectangle 1 + Rectangle 2 = 3
# Ratio des points retenus
ratio = np.sum(mask) / N
A_estimated = 4 * ratio # Aire du rectangle englobant × ratio
print("Nombre de points tirés :", N)
print("Nombre de points dans la région L :", np.sum(mask))
print("Aire estimée de la région L :", A_estimated, "(exacte :", A_L, ")")
print("Température moyenne estimée :", T_mean, "°C")
print("Erreur standard :", np.std(T_vals, ddof=1) / np.sqrt(len(T_vals)), "°C")
Nombre de points tirés : 500000 Nombre de points dans la région L : 375403 Aire estimée de la région L : 3.003224 (exacte : 3 ) Température moyenne estimée : 106.74004422054587 °C Erreur standard : 0.039276677949828614 °C
Comparaison : Monte Carlo vs quadrature déterministe en 2D¶
Pour une région rectangulaire simple, on peut utiliser scipy.integrate.dblquad().
Comparons les deux approches sur l'intégrale :
$$I = \int_0^1\int_0^1 \exp\left(-x^2 - y^2\right)\,\mathrm{d}x\,\mathrm{d}y$$
from scipy.integrate import dblquad
# Fonction à intégrer
def f_2d(y, x): # dblquad attend (y, x) dans cet ordre !
return np.exp(-x**2 - y**2)
# Quadrature déterministe
I_exact, err_quad = dblquad(f_2d, 0, 1, 0, 1)
print("Résultat par dblquad :", round(I_exact, 8))
print("Erreur estimée :", round(err_quad, 2))
# Monte Carlo
rng = np.random.default_rng(seed=789)
N = 100000
x = rng.uniform(0, 1, N)
y = rng.uniform(0, 1, N)
fx = np.exp(-x**2 - y**2)
I_mc = np.mean(fx) # Volume = 1 pour [0,1]×[0,1]
err_mc = np.std(fx, ddof=1) / np.sqrt(N)
print("Résultat par Monte Carlo avec N = ", N, ":")
print("Résultat par Monte Carlo :", round(I_mc, 8))
print("Erreur standard :", round(err_mc, 5))
print("Erreur réelle :", round(abs(I_mc - I_exact), 5))
Résultat par dblquad : 0.55774629 Erreur estimée : 0.0 Résultat par Monte Carlo avec N = 100000 : Résultat par Monte Carlo : 0.55743436 Erreur standard : 0.00068 Erreur réelle : 0.00031
Exemple en haute dimension : intégrale de configuration¶
En physique statistique, on calcule souvent des intégrales en $3N$ dimensions pour $N$ particules.
Considérons 2 particules dans une boîte cubique de côté $L=5$, avec potentiel de Lennard-Jones :
$$U(r) = 4\epsilon\left[\left(\frac{\sigma}{r}\right)^{12} - \left(\frac{\sigma}{r}\right)^6\right]$$
où $r = |\mathbf{r}_1 - \mathbf{r}_2|$ est la distance entre les particules.
On veut calculer la fonction de partition (simplifiée, pour avoir l'idée) :
$$Z \propto \int\int \exp\left(-\frac{U(r)}{k_B T}\right)\,\mathrm{d}^3\mathbf{r}_1\,\mathrm{d}^3\mathbf{r}_2$$
C'est une intégrale en 6 dimensions !
# Paramètres Lennard-Jones (argon)
epsilon = 1.0 # unités arbitraires
sigma = 1.0
kB = 1.0
T = 2.0
L = 5.0
def lennard_jones(r):
"""Potentiel de Lennard-Jones."""
if r < 0.5 * sigma: # éviter r → 0, sinon on a une singularité
return np.inf
sr6 = (sigma / r)**6
return 4 * epsilon * (sr6**2 - sr6)
rng = np.random.default_rng(seed=321)
N = 1000000
# Tirer N configurations de 2 particules
r1 = rng.uniform(0, L, (N, 3)) # positions de la particule 1
r2 = rng.uniform(0, L, (N, 3)) # positions de la particule 2
# Distance entre les particules
dr = r1 - r2
r = np.linalg.norm(dr, axis=1)
# Facteur de Boltzmann
U = np.array([lennard_jones(ri) for ri in r])
boltzmann = np.exp(-U / (kB * T))
# Intégrale (sans normalisation)
V = L**6 # volume de l'espace de configuration 6D
# (ce n'est pas une espace physique, juste mathématique)
Z_estimate = V * np.mean(boltzmann)
print("Estimation de Z (N=1000000) :", round(Z_estimate, 2))
print("Erreur standard :", round(V * np.std(boltzmann, ddof=1) / np.sqrt(N), 2))
Estimation de Z (N=1000000) : 15719.02 Erreur standard : 2.82
Remarque : cette intégrale en 6D serait totalement impraticable avec une grille régulière ($100^6 = 10^{12}$ points !), mais elle est calculable par Monte Carlo en quelques secondes.
À vous de faire les exercices 2.1 et 2.2 !¶
☕ Pause — 10 minutes¶
3 · Réduction de variance & échantillonnage pondéré¶
L'erreur Monte Carlo est proportionnelle à $\sigma_f / \sqrt{N}$.
Deux stratégies pour réduire l'erreur :
- Augmenter $N$ — coûteux (facteur 100 pour diviser l'erreur par 10)
- Réduire $\sigma_f$ — technique de réduction de variance
Une méthode puissante : échantillonnage pondéré (importance sampling).
Échantillonnage pondéré (importance sampling)¶
Au lieu d'échantillonner uniformément, on échantillonne selon une distribution $g(x)$ qui ressemble à $f(x)$ :
$$I = \int_a^b f(x)\,\mathrm{d}x = \int_a^b \frac{f(x)}{g(x)}\,g(x)\,\mathrm{d}x$$
Si $x_i \sim g(x)$, alors :
$$\hat{I}_N = \frac{1}{N}\sum_{i=1}^N \frac{f(x_i)}{g(x_i)}$$
Objectif : choisir $g(x)$ tel que $f(x)/g(x)$ soit presque constant → variance minimale !
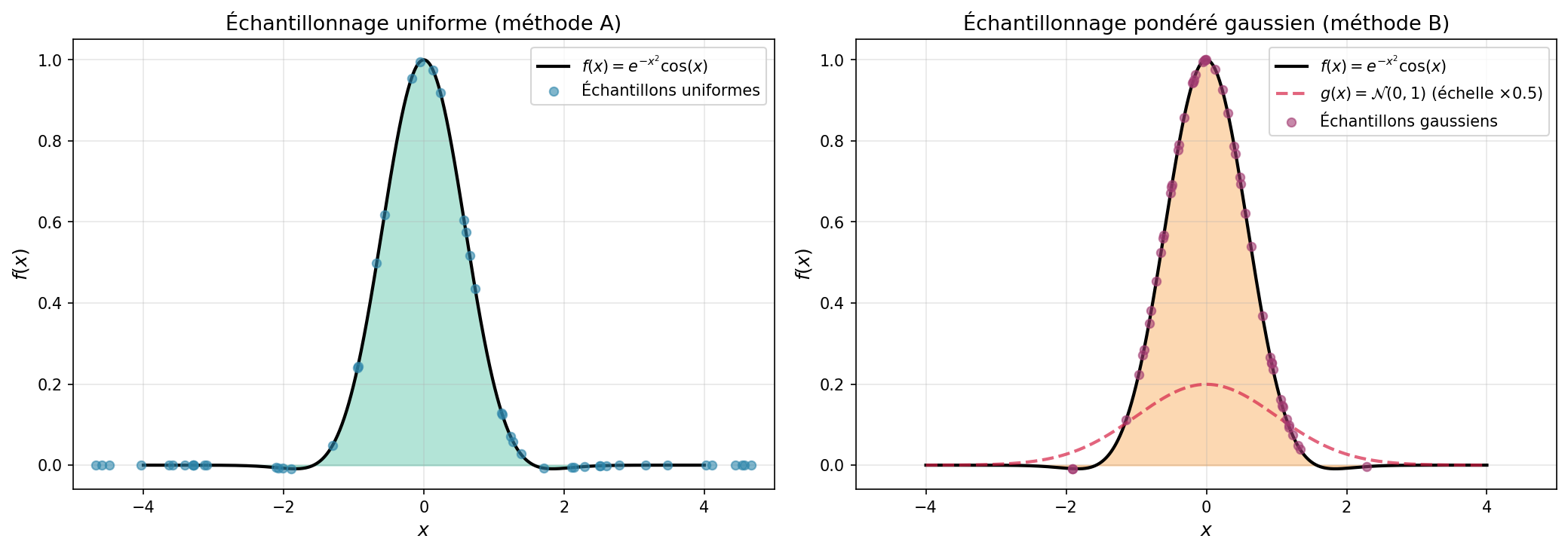
Exemple : intégrer $f(x) = e^{-x^2}\cos(x)$ sur $(−\infty, +\infty)$¶
L'intégrale exacte (par résidu ou calcul symbolique) est connue.
Méthode A : échantillonnage uniforme tronqué sur $[-5, 5]$
Méthode B : échantillonnage gaussien $g(x) = \frac{1}{\sqrt{2\pi}}e^{-x^2/2}$ (une fonction qui ressemble à f(x), mais une autre $f(x)$ peut demander une fonction $g(x)$ autre que la Gaussienne)
from scipy.stats import norm
from scipy.integrate import quad
def f_exp_x_squared_cos_x(x):
return np.exp(-x**2) * np.cos(x)
# Valeur exacte (calculée symboliquement ou numériquement)
I_exact, _ = quad(f_exp_x_squared_cos_x, -np.inf, np.inf)
print("Valeur exacte (par quad) : ", round(I_exact, 8))
rng = np.random.default_rng(seed=999)
N = 100000
# Méthode A : échantillonnage uniforme sur [-5, 5]
x_uniform = rng.uniform(-5, 5, N)
fx_uniform = f_exp_x_squared_cos_x(x_uniform)
I_uniform = 10 * np.mean(fx_uniform) # 10 = largeur de l'intervalle
err_uniform = 10 * np.std(fx_uniform, ddof=1) / np.sqrt(N)
print("I_hat = ", round(I_uniform, 8))
print("erreur standard = ", round(err_uniform, 8))
print("erreur réelle = ", round(abs(I_uniform - I_exact), 8))
Valeur exacte (par quad) : 1.38038845 I_hat = 1.37546651 erreur standard = 0.00902804 erreur réelle = 0.00492193
# Méthode B : échantillonnage pondéré
x_gauss = rng.normal(0, 1, N) # À partir de g(x), générer les points x on va donner à f(x)
g_vals = norm.pdf(x_gauss) # Obtenir la densité de probabilité g(x) pour chaque point x_gauss
fx_gauss = f_exp_x_squared_cos_x(x_gauss) # Évaluer f sur les points générés par g(x)
weights = fx_gauss / g_vals # poids d'importance normalisés par les densités de g(x)
I_importance = np.mean(weights) # L'estimateur d'intégrale est la moyenne des poids
err_importance = np.std(weights, ddof=1) / np.sqrt(N) # L'erreur standard est typique
# pour le Monte Carlo
print("I_hat = ", round(I_importance, 8))
print("erreur standard = ", round(err_importance, 8))
print("erreur réelle = ", round(abs(I_importance - I_exact), 8))
print("Ratio des erreurs standard de méthode uniform à",
"méthode gaussienne : ", round(err_uniform / err_importance, 1), "×")
I_hat = 1.38296457 erreur standard = 0.0028913 erreur réelle = 0.00257612 Ratio des erreurs standard de méthode uniform à méthode gaussienne : 3.1 ×
Observation : l'échantillonnage pondéré réduit la variance de manière très éfficace. On obtient plusieurs fois moins d'erreur avec le même nombre d'échantillons.
Exemple de science des matériaux : énergie moyenne de Boltzmann¶
En thermodynamique statistique, on calcule souvent :
$$\langle E \rangle = \frac{\int_0^\infty E \, e^{-E/(k_B T)}\,\mathrm{d}E}{\int_0^\infty e^{-E/(k_B T)}\,\mathrm{d}E}$$
La réponse analytique est $\langle E \rangle = k_B T$.
Testons avec Monte Carlo :
- Méthode A : échantillonnage uniforme tronqué sur $[0, 10 k_B T]$
- Méthode B : échantillonnage exponentiel $g(E) = \lambda e^{-\lambda E}$ avec $\lambda = 1/(k_B T)$
# Définir les paramètres
kB, T = 1.0, 2.0
beta, E_max, exact_mean = 1.0/(kB*T), 10*kB*T, kB * T
rng = np.random.default_rng(seed=111)
N = 100000
# Méthode A : uniforme sur [0, E_max]
E_uniform = rng.uniform(0, E_max, N)
boltz_uniform = np.exp(-beta * E_uniform)
numerator_A = E_uniform * boltz_uniform
denominator_A = boltz_uniform
mean_E_A = np.sum(numerator_A) / np.sum(denominator_A)
var_ratio_A = np.var(numerator_A / denominator_A, ddof=1)
print("Méthode A (uniforme) : <E> estimé = ", round(mean_E_A, 6), " (exact = ", \
round(exact_mean, 6), "), erreur = ", round(abs(mean_E_A - exact_mean), 4))
# Méthode B : échantillonnage exponentiel
E_exp = rng.exponential(scale=kB*T, size=N) # E ~ exp(-E/(kB*T))
# g(E) = beta * exp(-beta*E), donc poids = [E * exp(-beta*E)] / [beta * exp(-beta*E)] = E / beta
weights_B = E_exp # simplification car normalisation s'annule
mean_E_B = np.mean(weights_B)
err_B = np.std(weights_B, ddof=1) / np.sqrt(N)
print("Méthode B (exponentiel) : <E> estimé = ", round(mean_E_B, 6), " (exact = ", \
round(exact_mean, 6), "), erreur = ", round(abs(mean_E_B - exact_mean), 4))
Méthode A (uniforme) : <E> estimé = 1.990517 (exact = 2.0 ), erreur = 0.0095 Méthode B (exponentiel) : <E> estimé = 1.995075 (exact = 2.0 ), erreur = 0.0049
Échantillonnage stratifié (stratified sampling)¶
Une autre technique de réduction de variance : diviser le domaine en strates (sous-régions), échantillonner uniformément dans chaque strate.
Principe¶
- Diviser $[a, b]$ en $K$ strates égales : $[x_0, x_1], [x_1, x_2], \ldots, [x_{K-1}, x_K]$
- Tirer $n_k$ échantillons dans chaque strate $k$ (souvent $n_k = N/K$)
- Calculer l'estimateur :
$$\hat{I}_\text{strat} = \sum_{k=1}^{K} \frac{x_k - x_{k-1}}{n_k} \sum_{i=1}^{n_k} f(x_{k,i})$$
Avantages¶
- Couverture garantie : chaque région du domaine est échantillonnée
- Variance réduite : $\text{Var}(\hat{I}_\text{strat}) \leq \text{Var}(\hat{I}_\text{MC})$ toujours
- Pas de coût supplémentaire : même nombre d'évaluations de $f$
Réduction de variance¶
Pour $K$ strates de taille égale :
$$\text{Var}(\hat{I}_\text{strat}) = \frac{(b-a)^2}{NK} \sum_{k=1}^{K} \sigma_k^2$$
où $\sigma_k^2$ est la variance de $f$ dans la strate $k$.
Si $f$ varie beaucoup globalement mais peu localement, alors $\sum \sigma_k^2 \ll \sigma_\text{total}^2$ → grande réduction de variance !
# Exemple : intégrer e^(-x) sur [0, 1] avec échantillonnage stratifié
def monte_carlo_stratified(f, a, b, K, N, rng):
"""
Intégration Monte Carlo stratifiée.
K : nombre de strates
N : nombre total d'échantillons (répartis également entre strates)
"""
strata_edges = np.linspace(a, b, K+1)
n_per_strata = N // K
I_hat = 0.0
for k in range(K):
# Bornes de la strate k
x_left, x_right = strata_edges[k], strata_edges[k + 1]
width = x_right - x_left
# Échantillonner uniformément dans cette strate
x_strata = rng.uniform(x_left, x_right, n_per_strata)
f_strata = f(x_strata)
# Contribution de cette strate
I_hat += width * np.mean(f_strata)
return I_hat
# Comparaison MC classique vs stratifié
def f_exp(x):
return np.exp(-x)
I_exact = 1 - np.exp(-1) # ≈ 0.6321
rng = np.random.default_rng(seed=789)
N = 10000
K = 10 # 10 strates
n_trials = 500
errors_mc = []
errors_strat = []
for _ in range(n_trials):
# MC classique
x_mc = rng.uniform(0, 1, N)
I_mc = np.mean(f_exp(x_mc))
errors_mc.append((I_mc - I_exact)**2)
# MC stratifié
I_strat = monte_carlo_stratified(f_exp, 0, 1, K, N, rng)
errors_strat.append((I_strat - I_exact)**2)
rmse_mc = np.sqrt(np.mean(errors_mc))
rmse_strat = np.sqrt(np.mean(errors_strat))
print("Intégrale de e^(-x) sur [0, 1] avec", N, "échantillons :")
print("MC classique : RMSE =", round(rmse_mc, 6))
print("MC stratifié (K=", K, ") : RMSE =", round(rmse_strat, 6))
print("Réduction de variance : facteur", round(rmse_mc / rmse_strat, 2))
Intégrale de e^(-x) sur [0, 1] avec 10000 échantillons : MC classique : RMSE = 0.001766 MC stratifié (K= 10 ) : RMSE = 0.000185 Réduction de variance : facteur 9.53
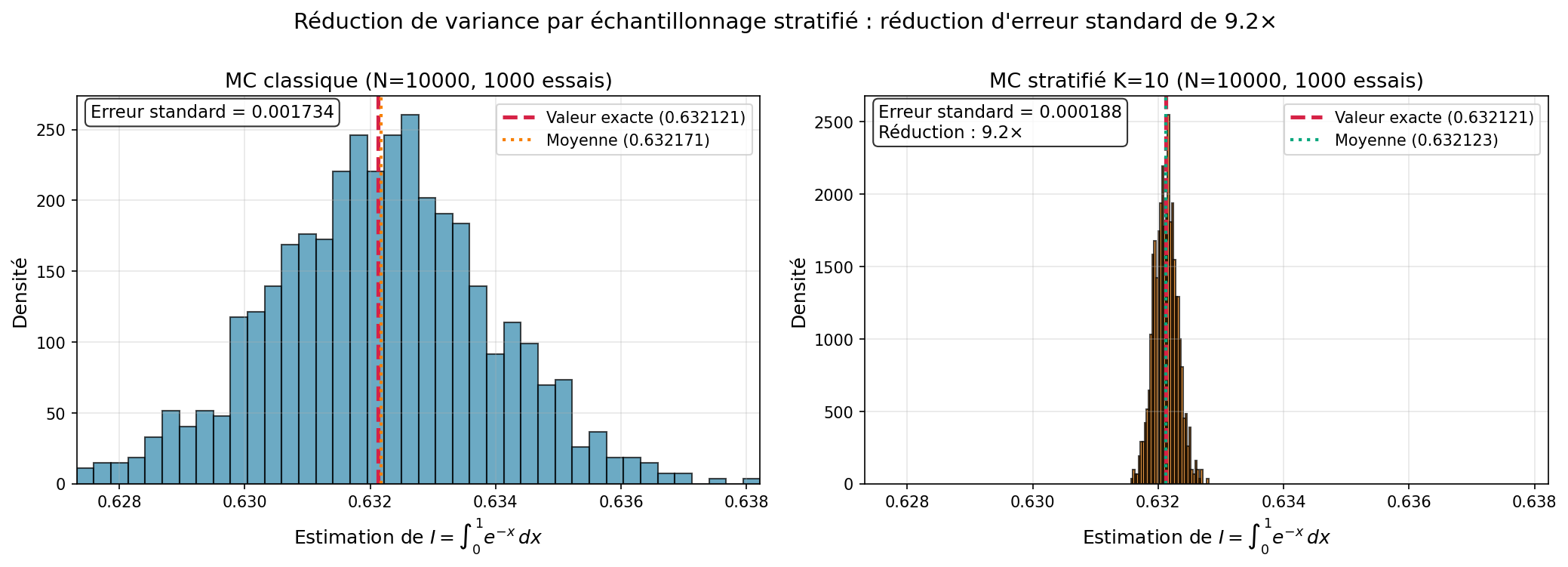
Observation : L'échantillonnage stratifié produit une distribution d'estimations beaucoup plus concentrée autour de la vraie valeur. La variance est réduite sans coût supplémentaire !
À vous de faire les exercices 3.1 — 3.3 !¶
Mini-projet noté¶
Contexte : refroidissement contrôlé d'un acier hypoeutectoïde (~0.35% C).
Objectif : relier données expérimentales, intégration numérique et Monte Carlo dans un même workflow.
- Données dilatométriques : transformation austénite → ferrite/perlite
- Données thermiques : calcul d'enthalpie et chaleur latente
- Géométrie en L : estimation de température moyenne par Monte Carlo
Mini-projet — tâches techniques¶
| Partie | Travail demandé | Techniques / fonctions |
|---|---|---|
| 1. Dilatométrie | Identifier les zones linéaires, estimer $A_{r3}$ et $A_{r1}$ | np.polyfit, CubicSpline, brentq |
| 2. Bilan enthalpique | Calculer $\Delta H$ et $H(T)$, puis chaleur latente | trapezoid, simpson, quad, cumulative_trapezoid |
| 3. Section en L | Estimer $\langle T \rangle$ sur domaine irrégulier | Monte Carlo (rejet), comparaison dblquad |
Mini-projet — rendu attendu¶
- Notebook clair et structuré avec fonctions réutilisables où besoin
- Graphiques légendés avec axes + unités
seedfixé pour la reproductibilité
Points clés de la séance¶
| Concept | Ce qu'il faut retenir |
|---|---|
np.random.default_rng(seed) |
Générateur moderne ; reproductible avec seed |
| Estimateur MC | (b-a) * np.mean(f(rng.uniform(a, b, N))) — erreur $\mathcal{O}(1/\sqrt{N})$, indépendante de la dimension |
| Erreur standard | (b-a) * np.std(f(X), ddof=1) / np.sqrt(N) |
| MC multi-dimensionnel | V * np.mean(f(X)) avec $V$ = volume du domaine ; avantage pour $d \geq 4$ |
| Importance sampling | Tirer $X$ selon $g \approx \lvert f \rvert$ ; estimer np.mean(f(X) / g(X)) |
| Échantillonnage stratifié | Diviser le domaine en strates, tirer uniformément dans chacune ; réduit la variance sans coût supplémentaire |