Un lien vers Google Colab qui peut faire tourner le notebook qui contient les exercices se trouve ici :
https://colab.research.google.com/github/nickcollins-craft/USMA1Q-Methodes-Numeriques/blob/main/
Plan du cours¶
| Jour | Sujet |
|---|---|
| 03 mars | Fondamentaux de la programmation en Python |
| 04 mars (matin) | Fonctions, listes approfondies, fichiers et graphiques |
| 04 mars (après-midi) | Calcul numérique avec NumPy |
| 11 mars (matin) | Tableaux en mémoire, matrices & précision numérique |
| 11 mars (après-midi) | Résolution des systèmes linéaires |
| 18 mars (matin) | Interpolation & recherche des racines |
| 18 mars (après-midi) | Systèmes d'équations non linéaires |
| 25 mars | Intégration numérique |
| 02 avril | Équations différentielles |
| 08 avril | Examen |
Plan de la séance (indicatif)¶
| Horaire | Sujet |
|---|---|
| 0:00 – 1:00 | Newton–Raphson vectoriel |
| 1:00 – 1:45 | Jacobien numérique et recherche linéaire |
| 1:45 – 1:55 | ☕ Pause |
| 1:55 – 2:35 | Outils SciPy pour les systèmes non linéaires |
| 2:35 – 3:30 | Mini-projet guidé |
Motivation — systèmes non linéaires en science des matériaux¶
Les équations scalaires (séance 6) ne suffisent pas toujours :
| Problème | Système d'équations |
|---|---|
| Équilibre de phases binaire | Égalité des potentiels chimiques de deux phases |
| Cinétique couplée | Concentrations stationnaires de plusieurs espèces |
| Plasticité | Retour sur la surface seuil (plusieurs inconnues) |
| Éléments finis non linéaires | Résidu global $\mathbf{F}(\mathbf{u}) = \mathbf{0}$ |
Idée centrale : on généralise la recherche de racine scalaire $f(x)=0$ à la recherche d'un vecteur $\mathbf{x}$ tel que $\mathbf{F}(\mathbf{x}) = \mathbf{0}$, où $\mathbf{F} : \mathbb{R}^n \to \mathbb{R}^n$.
1 · Newton–Raphson vectoriel¶
Formulation vectorielle¶
On cherche $\mathbf{x}^* \in \mathbb{R}^n$ tel que $\mathbf{F}(\mathbf{x}^*) = \mathbf{0}$, avec $\mathbf{F} : \mathbb{R}^n \to \mathbb{R}^n$.
La matrice Jacobienne¶
Le Jacobien est l'analogue vectoriel de la dérivée :
$$J_{ij} = \frac{\partial F_i}{\partial x_j}$$
C'est une matrice $n \times n$ qui décrit la sensibilité de chaque composante $F_i$ à un changement de chaque variable $x_j$.
L'étape de Newton¶
- Linéariser $\mathbf{F}$ autour du point courant $\mathbf{x}_k$ :
$$\mathbf{F}(\mathbf{x}_k + \Delta\mathbf{x}) \approx \mathbf{F}(\mathbf{x}_k) + J(\mathbf{x}_k) \, \Delta\mathbf{x} = \mathbf{0}$$
- Résoudre le système linéaire (c'est ici qu'on utilise la séance 5 !) :
$$J(\mathbf{x}_k) \, \Delta\mathbf{x} = -\mathbf{F}(\mathbf{x}_k)$$
Mettre à jour : $\mathbf{x}_{k+1} = \mathbf{x}_k + \Delta\mathbf{x}$
Répéter jusqu'à ce que $\|\mathbf{F}(\mathbf{x}_k)\| < \text{tolérance}$
Connexion séance 5 : chaque itération Newton = résolution d'un système linéaire
Convergence de Newton–Raphson¶
La bonne nouvelle : la convergence est quadratique près de la solution :
$$\|\mathbf{x}_{k+1} - \mathbf{x}^*\| \leq C \|\mathbf{x}_k - \mathbf{x}^*\|^2$$
Le nombre de décimales correctes double à chaque itération !
La mauvaise nouvelle :
- Converge seulement si le point de départ est proche de la solution
- Nécessite le calcul du Jacobien à chaque itération (peut être très coûteux pour les grands systèmes)
- Peut diverger si on part loin de la solution (le pas $\Delta\mathbf{x}$ peut être trop grand)
- Peut entrer dans un cycle limite dans quelques situation défavorable (mal conditionné)
Application — tangente commune (équilibre de phases)¶
On dispose de deux courbes d'énergie libre :
$$G_\alpha(x) = 10(x-0.2)^2 + 0.1 \qquad G_\beta(x) = 10(x-0.8)^2 + 0.05$$
L´équilibre est obtenue quand le potentiel chimique de chaque composant est égal dans les deux phases, et le potentiel chimique n'est rien autre que la dérivée de l'énergie libre partiel par rapport du composant. Donc, la condition d'équilibre est trouvée quand les tangentes sont égales.
Les conditions de la tangente commune sont :
$F_1(x_1, x_2) = G'_\alpha(x_1) - G'_\beta(x_2) = 0$ (les pentes des tangentes sont identiques)
$F_2(x_1, x_2) = G'_\alpha(x_1) - \frac{G_\beta(x_2) - G_\alpha(x_1)}{x_2 - x_1} = 0$ (les tangentes passent par les mêmes points)
→ système $2 \times 2$ non linéaire !
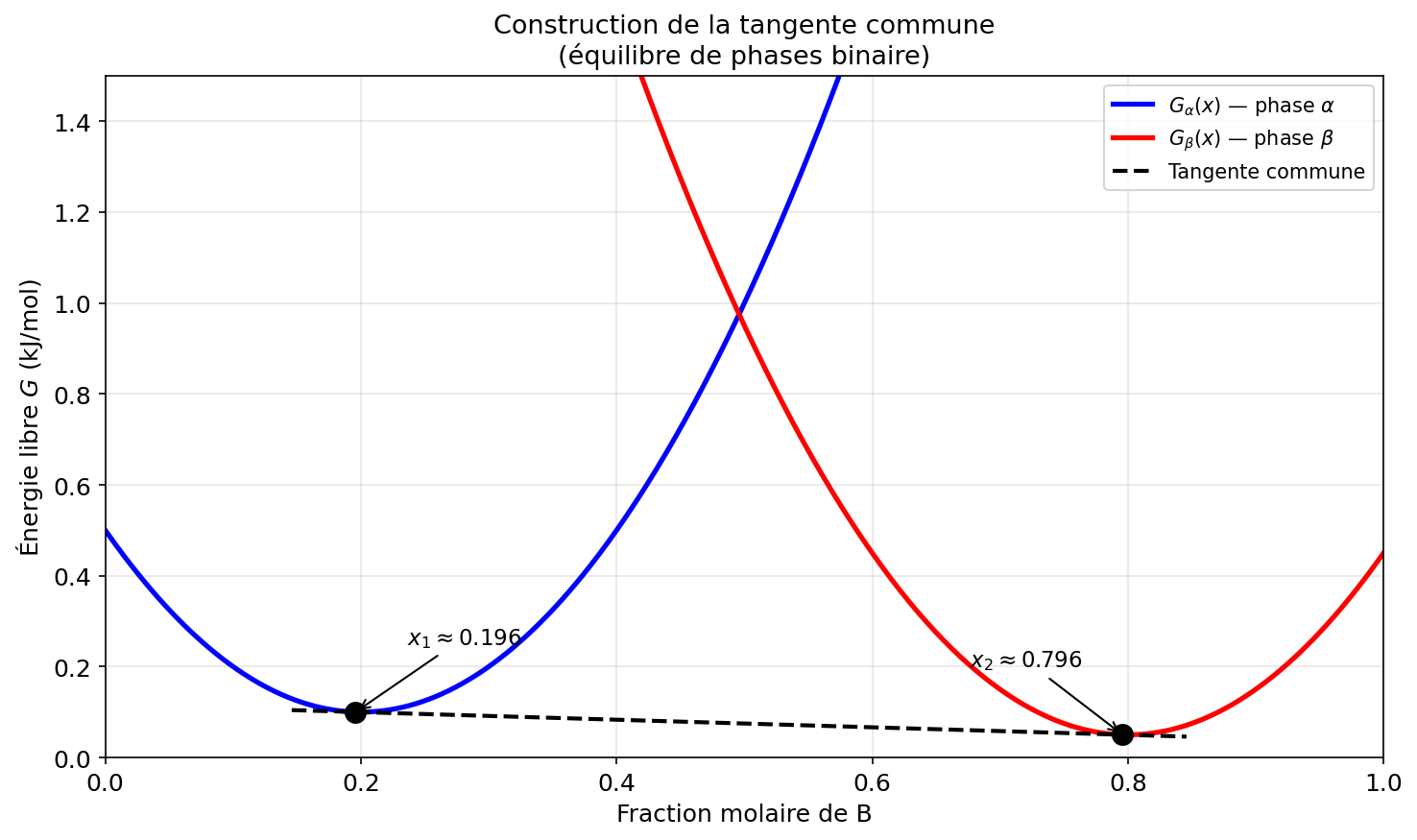
Jacobien analytique pour la tangente commune¶
$$J = \begin{pmatrix} G''_\alpha(x_1) & -G''_\beta(x_2) \\\\ G''_\alpha(x_1) + \frac{G'_\alpha(x_1)}{x_{2} - x_{1}} - \frac{G_{\beta}(x_{2}) - G_{\alpha}(x_{1})}{x_{2} - x_{1}^2} & -\frac{G'_\beta(x_2)}{x_{2} - x_{1}} + \frac{G_{\beta}(x_{2}) - G_{\alpha}(x_{1})}{x_{2} - x_{1}^2} \end{pmatrix}$$
# ── Démonstration : Newton–Raphson pour la tangente commune ──
import numpy as np
def G_alpha(x):
return 10.0*(x - 0.2)**2 + 0.1
def G_beta(x):
return 10.0*(x - 0.8)**2 + 0.05
def dG_alpha(x):
return 20.0*(x - 0.2)
def dG_beta(x):
return 20.0*(x - 0.8)
def F(x): # F = résiduelle
x1, x2 = x[0], x[1]
return np.array([dG_alpha(x1) - dG_beta(x2), dG_alpha(x1) - (G_beta(x2) - G_alpha(x1))/(x2 - x1)])
def J(x): # J = Jacobien
x1, x2 = x[0], x[1]
dG = G_beta(x2) - G_alpha(x1)
return np.array([[20.0, -20.0],
[20.0 + dG_alpha(x1)/(x2 - x1) - (G_beta(x2) - G_alpha(x1))/(x2 - x1)**2, -dG_beta(x2)/(x2 - x1) + (G_beta(x2) - G_alpha(x1))/(x2 - x1)**2]])
x = np.array([0.3, 0.7]) # x0 = point de départ
print("Iter | x1 x2 | ||F||")
for k in range(10):
Fk = F(x)
print("%4d | %.6f %.6f | %.2e" % (k, x[0], x[1], np.linalg.norm(Fk))) # Les instructions marquées avec %...
# sont des formats de chaîne de caractères (string formatting) pour afficher les valeurs de manière lisible. On n'a pas besoin de les comprendre dans ce cours.
if np.linalg.norm(Fk) < 1e-12:
break
dx = np.linalg.solve(J(x), -Fk) # résoudre J·Δx = -F
x = x + dx # x ← x + Δx
À vous de faire l'exercice 1 !¶
2 · Jacobien numérique et recherche linéaire¶
Problème 1 : le Jacobien analytique est difficile à calculer¶
Pour un système de $n$ équations, calculer $J$ analytiquement requiert $n^2$ dérivées partielles. C'est difficile et un grand source d'erreurs.
Solution : approximation par différences finies
$$\frac{\partial F_i}{\partial x_j} \approx \frac{F_i(\mathbf{x} + \delta \mathbf{e}_j) - F_i(\mathbf{x})}{\delta}$$
Coût : $n$ évaluations supplémentaires de $\mathbf{F}$ par itération.
# ── Jacobien numérique ──
def jacobien_numerique(F, x, delta=1e-8):
n = len(x)
F0 = F(x)
J = np.zeros((n, n))
for j in range(n):
x_pert = x.copy() # copie du point courant
x_pert[j] += delta # perturbation de la j-ème variable
J[:, j] = (F(x_pert) - F0)/delta # colonne j du Jacobien
return J
# Vérification : comparer au Jacobien analytique
x_test = np.array([0.3, 0.7])
print("Jacobien analytique :")
print(J(x_test))
print("Jacobien numérique :")
print(jacobien_numerique(F, x_test))
Problème 2 : le pas de Newton peut être trop grand¶
Si on part loin de la solution, le pas $\Delta\mathbf{x}$ peut nous faire aller dans la mauvaise direction.
Solution : recherche linéaire (line search)
Au lieu de $\mathbf{x} \leftarrow \mathbf{x} + \Delta\mathbf{x}$, on cherche un pas $\alpha \in (0, 1]$ :
$$\mathbf{x} \leftarrow \mathbf{x} + \alpha \, \Delta\mathbf{x}$$
Algorithme de rétréci (backtracking line search) :
- Commencer avec $\alpha = 1$ (le pas de Newton complet)
- Si $\|\mathbf{F}(\mathbf{x} + \alpha \Delta\mathbf{x})\| \geq \|\mathbf{F}(\mathbf{x})\|$, diviser $\alpha$ par 2
- Répéter jusqu'à obtenir une réduction de la norme
# ── Newton–Raphson avec recherche linéaire ──
def newton_avec_recherche_lineaire(F, J_func, x0, tol=1e-10, max_iter=50):
x = x0.copy() # Copier le point de départ pour éviter de le modifier
for k in range(max_iter):
Fk = F(x)
if np.linalg.norm(Fk) < tol: # convergé (converged)
break
dx = np.linalg.solve(J_func(x), -Fk) # direction de Newton
# Recherche linéaire par rétréci (backtracking line search)
alpha = 1.0
norme0 = np.linalg.norm(Fk)
while np.linalg.norm(F(x + alpha*dx)) >= norme0: # Le pas est trop grand et nous
# a donné une valeur de F plus grande que celle au point courant
alpha *= 0.5 # Diminue le pas de moitié
if alpha < 1e-14: # Si le pas devient trop petit, on arrête la recherche
# linéaire pour éviter les problèmes numériques
break
x = x + alpha*dx # On met à jour x avec le pas trouvé pour avoir
# un mis-à-jour optimisé
return x
# Utilisation avec le Jacobien numérique
x_sol = newton_avec_recherche_lineaire(F,
lambda x: jacobien_numerique(F, x) # lambda x:
# jacobien_numerique(F, x) est une fonction anonyme
# qui prend un argument x et retourne le Jacobien
# numérique de F à ce point x
, np.array([0.3, 0.7]))
print("Solution :", x_sol)
print("||F(x*)|| :", np.linalg.norm(F(x_sol)))
Considerons la fonction
$$F(x)=\tan^{-1}(x)$$
Testons nos solveurs de Newton-Raphson pur et avec recherche linéaire et voyons la convergence (ou pas !).
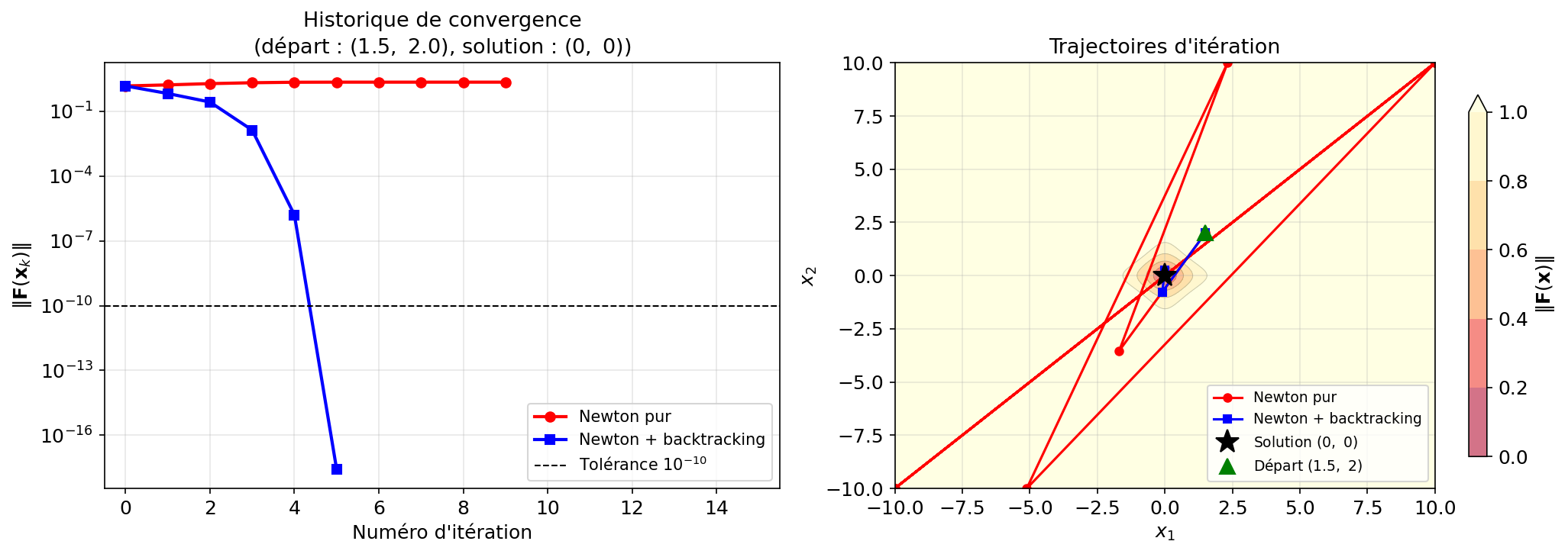
À vous de faire les exercices 2.1 et 2.2 !¶
☕ Pause — 10 minutes¶
3 · Outils SciPy pour les systèmes non linéaires¶
scipy.optimize.root¶
from scipy.optimize import root # root = racine
sol = root(F, x0, method='hybr') # hybr = hybride (Broyden–Powell)
Méthodes disponibles :
| Méthode | Description |
|---|---|
'hybr' |
Hybride Powell–Broyden — robuste, recommandée par défaut |
'lm' |
Levenberg–Marquardt — très robuste, gère les problèmes sur-déterminés |
'broyden1' |
Broyden — met à jour le Jacobien approximatif sans recalcul |
Levenberg–Marquardt et Broyden¶
Levenberg–Marquardt (LM) — cherche le minimum de $\|\mathbf{F}(\mathbf{x})\|^2$ : $$\Delta\mathbf{x} = -(J^T J + \lambda I)^{-1} J^T \mathbf{F}$$
- Pour $\lambda \to 0$ : Newton
- Pour $\lambda \to \infty$ : descente de gradient (robuste loin de la solution)
- $\lambda$ est adapté automatiquement : Newton quand on est proche, gradient quand on est loin
Broyden — méthode quasi-Newton :
- Évite de recalculer $J$ à chaque itération (coûteux pour les grands systèmes !)
- Met à jour une approximation $B_k \approx J(\mathbf{x}_k)$ à partir des étapes précédentes
- Convergence super-linéaire (moins que Newton mais moins coûteux)
Diagnostics de convergence¶
Toujours vérifier que la solution est correcte :
sol = root(F, x0, method='hybr')
print("Convergé :", sol.success) # success = réussi
print("||F(x*)|| :", np.linalg.norm(sol.fun)) # doit être ≈ 0 !
print("Solution x* :", sol.x)
⚠️ Un
sol.success = Truene garantit pas que vous avez la bonne solution — vérifiez toujours que $\|\mathbf{F}(\mathbf{x}^*)\|$ est bien proche de zéro.
# ── Démonstration : scipy.optimize.root ──
import numpy as np
from scipy.optimize import root # root = racine vectorielle
def G_alpha(x):
return 10.0 * (x - 0.2)**2 + 0.1
def G_beta(x):
return 10.0 * (x - 0.8)**2 + 0.05
def dG_alpha(x):
return 20.0 * (x - 0.2)
def dG_beta(x):
return 20.0 * (x - 0.8)
def F(x):
dx = x[1] - x[0]
return [dG_alpha(x[0]) - dG_beta(x[1]),
dG_alpha(x[0]) - (G_beta(x[1]) - G_alpha(x[0])) / dx]
sol = root(F, x0=[0.3, 0.7], method='hybr') # hybr = hybride
print("Convergé :", sol.success) # success = réussi
print("Solution x* :", sol.x)
print("||F(x*)|| :", np.linalg.norm(sol.fun))
À vous de faire l'exercice 3 !¶
Mini-projet — Analyse thermique d'une courbe de refroidissement¶
Données fournies (dossier seance_7/) :
courbe_refroidissement_alliage.csv— temps (s) et température (°C) lors du refroidissement d'un alliage binaire A–Bdonnees_dsc.csv— température (°C) et flux thermique (mW/mg) mesurés par DSCdiagramme_phases.csv— composition $x_B$, $T_\text{liquidus}$ et $T_\text{solidus}$ (°C)
Composition de l'alliage : $x_B = 0.30$
Tâches du mini-projet¶
- Charger la courbe de refroidissement, tracer $T(t)$
- Ajuster un spline ; calculer et tracer $\mathrm{d}T/\mathrm{d}t$ en fonction du temps
- Détecter le début de la solidification : maximum de $\mathrm{d}^{2}T/\mathrm{d}t^{2}$ ; marquer la température correspondante
- Charger les données du diagramme de phases ; interpoler et tracer les courbes liquidus/solidus
- Pour la composition $x_B = 0.30$, trouver $T_\text{liquidus}$ et $T_\text{solidus}$; comparer avec la température d'arrêt détectée en étape 3.
- À partir des données DSC, calculer la chaleur latente en intégrant le pic de flux thermique
- Écrire votre propre solveur Newton–Raphson (avec Jacobien numérique et recherche linéaire) ; l'utiliser pour trouver les compositions de la tangente commune des courbes d'énergie libre fournies
Rendu : notebook .ipynb complété, à remettre mardi soir
Points clés de la séance¶
| Concept | Ce qu'il faut retenir |
|---|---|
F(x*) = 0 vectoriel |
Généralise la recherche de racine scalaire à $\mathbf{F} : \mathbb{R}^n \to \mathbb{R}^n$ |
Jacobien J |
$J_{ij} = \partial F_i / \partial x_j$ — analogue vectoriel de la dérivée ; matrice $n \times n$ |
| Itération de Newton | Résoudre $J \Delta\mathbf{x} = -\mathbf{F}$, puis $\mathbf{x} \leftarrow \mathbf{x} + \Delta\mathbf{x}$ — utilise np.linalg.solve() |
| Convergence quadratique | Le nombre de décimales correctes double à chaque itération — mais seulement près de la solution |
| Jacobien numérique | $\partial F_i/\partial x_j \approx (F_i(\mathbf{x}+\delta\mathbf{e}_j) - F_i(\mathbf{x}))/\delta$ — $n$ évaluations supplémentaires de $\mathbf{F}$, évite les dérivées analytiques |
| Recherche linéaire | alpha *= 0.5 jusqu'à réduction de ‖F‖ — protège contre les pas trop grands loin de la solution |
scipy.optimize.root |
root(F, x0, method='hybr') — solveur robuste prêt à l'emploi |
| Levenberg–Marquardt | $\Delta\mathbf{x} = -(J^TJ + \lambda I)^{-1}J^T\mathbf{F}$ — se comporte comme Newton ($\lambda\to 0$) ou descente de gradient ($\lambda\to\infty$) |
| Broyden | Mise à jour approchée du Jacobien — moins coûteux que Newton, convergence super-linéaire |
| Vérification | Toujours contrôler np.linalg.norm(sol.fun) ≈ 0 — sol.success = True seul ne garantit pas la bonne solution |